Guía completa
Manual de algoritmia en C y C++
Esta guía cubre los conceptos esenciales que necesitas para programar algoritmos eficientemente: desde la sintaxis de C hasta el STL de C++, pasando por las estructuras de datos más utilizadas y los algoritmos clásicos que debes conocer.
Lenguaje base
C para algoritmia
C es el lenguaje de referencia para estudiar algoritmia por su cercanía con el hardware y su control explícito de memoria. Entender C profundamente te ayuda a comprender qué pasa "debajo" cuando usas lenguajes de más alto nivel.
Variables y tipos de datos esenciales
Los tipos más usados en problemas de algoritmia son int (enteros),
long long (enteros grandes, hasta ~9.2×10¹⁸), double (decimales)
y char (caracteres). Declara las variables lo más cerca posible de donde las usas.
Condicionales y ciclos
El if/else y el operador ternario ?: controlan el flujo. Para
iteraciones usa for cuando conoces el número de repeticiones y while
cuando dependes de una condición. El ciclo do-while garantiza al menos una ejecución.
Funciones y arreglos
Divide tu solución en funciones pequeñas y bien nombradas. Los arreglos en C son contiguos en
memoria: int arr[100] reserva 100 enteros. Pasa arreglos a funciones con un puntero
y el tamaño por separado, ya que C no guarda la longitud automáticamente.
Ejemplo 1: suma de un arreglo
#include <stdio.h>
/* Retorna la suma de los primeros n elementos de arr */
int sumaArreglo(int arr[], int n) {
int total = 0;
for (int i = 0; i < n; i++) {
total += arr[i];
}
return total;
}
int main(void) {
int datos[] = {3, 7, 2, 9, 4};
int n = sizeof(datos) / sizeof(datos[0]);
printf("Suma: %d\n", sumaArreglo(datos, n));
return 0;
}
Suma de arreglo en C. El truco de sizeof(arr)/sizeof(arr[0]) calcula la cantidad de elementos solo dentro del ámbito donde el arreglo fue declarado.
Ejemplo 2: búsqueda lineal con función
#include <stdio.h>
/* Retorna el índice de 'objetivo' en arr, o -1 si no existe */
int busquedaLineal(int arr[], int n, int objetivo) {
for (int i = 0; i < n; i++) {
if (arr[i] == objetivo)
return i;
}
return -1;
}
int main(void) {
int datos[] = {10, 25, 8, 42, 3};
int n = sizeof(datos) / sizeof(datos[0]);
int pos = busquedaLineal(datos, n, 42);
if (pos != -1)
printf("Encontrado en índice %d\n", pos);
else
printf("No encontrado\n");
return 0;
}
Búsqueda lineal: O(n) en el peor caso. Funciona en arreglos desordenados.
📝 Nota
Cuando uses memoria dinámica (malloc/calloc), siempre libérala con
free(). Los fugas de memoria no causan errores inmediatos, pero degradan el rendimiento
en programas largos y pueden ser difíciles de depurar.
El siguiente paso
C++ para algoritmia
C++ extiende C con orientación a objetos, pero para algoritmia lo más valioso es su Standard Template Library (STL): contenedores genéricos, iteradores y algoritmos ya implementados y probados. Usarlos correctamente marca la diferencia en competencias y proyectos.
Entrada/salida con iostream
Usa cin y cout en lugar de scanf/printf. Para competencias,
agrega ios::sync_with_stdio(false); cin.tie(NULL); al inicio del main
para acelerar significativamente la lectura de datos grandes.
Vector: el arreglo dinámico de C++
std::vector<int> es un arreglo que crece automáticamente. Ofrece acceso
aleatorio en O(1), inserción al final en O(1) amortizado, y la conveniencia de conocer su
tamaño con .size(). Es la estructura por defecto cuando no sabes el tamaño exacto
de antemano.
Ejemplo 1: uso de vector y sort
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
// Leer n números y almacenarlos en un vector
int n;
cin >> n;
vector<int> nums(n);
for (int i = 0; i < n; i++) cin >> nums[i];
// Ordenar en O(n log n) con std::sort
sort(nums.begin(), nums.end());
cout << "Ordenados: ";
for (int x : nums) cout << x << " ";
cout << "\n";
return 0;
}
std::sort implementa Introsort (híbrido de quicksort, heapsort y insertion sort) con complejidad garantizada O(n log n).
Ejemplo 2: map y set para frecuencias
#include <iostream>
#include <map>
using namespace std;
int main() {
// Contar frecuencia de palabras
map<string, int> freq;
string palabra;
while (cin >> palabra) {
freq[palabra]++;
}
for (auto& [key, val] : freq) {
cout << key << ": " << val << "\n";
}
return 0;
}
std::map es un árbol balanceado (BST) con operaciones O(log n). Si solo necesitas búsqueda rápida sin orden, usa unordered_map con O(1) promedio.
💡 Tip STL esencial
Para competencias y proyectos, domina al menos: vector, map,
unordered_map, set, queue, stack,
priority_queue y los algoritmos sort, binary_search,
lower_bound y upper_bound. Con estos ya puedes resolver la mayoría de
los problemas de nivel intermedio.
Referencias y paso por referencia
A diferencia de C, en C++ puedes pasar por referencia con &. Esto evita copiar
estructuras grandes y permite modificar el valor original desde una función. Usa
const& cuando no necesitas modificar el parámetro para expresar esa intención
explícitamente y permitir al compilador optimizar.
Organizar la información
Estructuras de datos
Una estructura de datos es una forma de organizar información en memoria para que ciertas operaciones —búsqueda, inserción, eliminación— sean eficientes. Elegir la estructura correcta frecuentemente es la mitad de la solución.
Arreglos (Arrays)
Colección de elementos del mismo tipo almacenados de forma contigua en memoria. Acceso aleatorio en O(1), pero inserción y eliminación en posiciones intermedias requieren O(n) por el desplazamiento de elementos. Úsalos cuando el tamaño es conocido y el acceso por índice es frecuente.
Listas enlazadas
Cada nodo contiene el dato y un puntero al siguiente. Inserción y eliminación en O(1) si tienes
el puntero al nodo previo, pero el acceso por posición es O(n). En la práctica, std::list
de C++ se usa poco porque los vectores suelen ser más eficientes en caché.
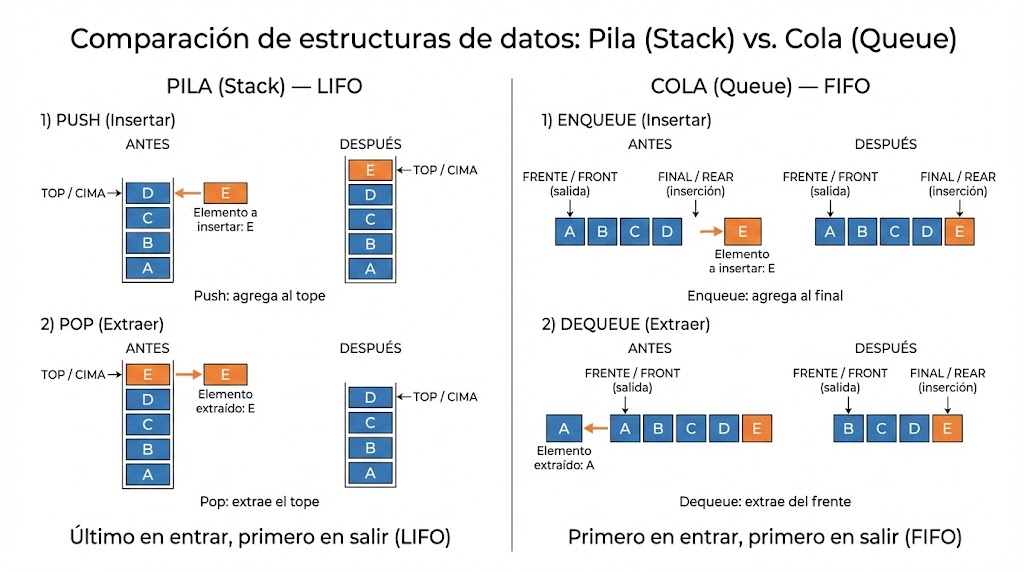
Pilas (Stack) y Colas (Queue)
La pila (LIFO) permite insertar y extraer solo por el tope. Es fundamental para recursión, evaluación de expresiones y DFS iterativo. La cola (FIFO) extrae por el frente e inserta por el final; es clave para BFS y simulaciones de procesos.
Árboles
Un árbol binario de búsqueda (BST) permite búsqueda, inserción y eliminación en O(log n)
si está balanceado. Los árboles AVL y los Red-Black Trees garantizan el balance
automáticamente. En C++, std::map y std::set están implementados como
árboles Red-Black.
Tablas hash (Hash Tables)
Ofrecen búsqueda, inserción y eliminación en O(1) promedio. La eficiencia depende de la función
hash y el manejo de colisiones. En C++, unordered_map y unordered_set
son las implementaciones estándar.
¿Cuándo usar cada estructura?
| Estructura | Acceso | Inserción | Búsqueda | Úsala cuando… |
|---|---|---|---|---|
| Arreglo / Vector | O(1) | O(n)* | O(n) | Acceso por índice frecuente, tamaño relativamente fijo. |
| Lista enlazada | O(n) | O(1) | O(n) | Muchas inserciones/eliminaciones en posiciones arbitrarias. |
| Stack / Queue | Solo tope/frente | O(1) | — | DFS (stack), BFS (queue), historial de acciones. |
| BST / Map / Set | O(log n) | O(log n) | O(log n) | Datos ordenados, rangos, mínimo/máximo dinámico. |
| Hash / Unordered | O(1) prom. | O(1) prom. | O(1) prom. | Frecuencias, lookups rápidos sin necesitar orden. |
*Inserción al final de vector es O(1) amortizado. Al inicio o en posición arbitraria es O(n).
Herramientas fundamentales
Algoritmos clásicos
Hay un conjunto de algoritmos que todo programador debe conocer porque aparecen una y otra vez en problemas reales. No hace falta memorizarlos: el objetivo es entender cuándo aplica cada uno y ser capaz de implementarlo sin referencia.
Búsqueda lineal y búsqueda binaria
La búsqueda lineal recorre todos los elementos hasta encontrar el objetivo: O(n), funciona en arreglos no ordenados. La búsqueda binaria aprovecha el orden para dividir el espacio de búsqueda a la mitad en cada paso: O(log n). Para n=1,000,000, la búsqueda binaria necesita solo ~20 comparaciones.
// Búsqueda binaria iterativa en C++ (arreglo ordenado)
int binaria(vector<int>& arr, int objetivo) {
int izq = 0, der = arr.size() - 1;
while (izq <= der) {
int mid = izq + (der - izq) / 2; // evita overflow
if (arr[mid] == objetivo) return mid;
if (arr[mid] < objetivo) izq = mid + 1;
else der = mid - 1;
}
return -1; // no encontrado
}
Usar mid = izq + (der-izq)/2 en lugar de (izq+der)/2 previene desbordamiento entero cuando los índices son grandes.
Algoritmos de ordenamiento
Los algoritmos simples como Bubble Sort y Selection Sort tienen
O(n²) y sirven solo para conjuntos pequeños o para aprender el concepto. En la práctica, usa
siempre std::sort de C++ que implementa Introsort con O(n log n) garantizado.
Merge Sort divide el arreglo en dos mitades, ordena cada mitad recursivamente y las fusiona en O(n log n). Es estable (mantiene el orden relativo de elementos iguales) y predecible. Quick Sort elige un pivote, particiona alrededor de él y ordena las particiones recursivamente: O(n log n) promedio, O(n²) en el peor caso (que se evita con pivote aleatorio).
💡 Regla práctica de ordenamiento
Usa std::sort siempre que puedas. Solo implementa tu propio algoritmo de
ordenamiento en competencias que lo pidan explícitamente, para aprender, o cuando necesites
una variante específica como conteo de inversiones con Merge Sort.
BFS — Búsqueda en Anchura
BFS (Breadth-First Search) explora un grafo nivel por nivel usando una cola. Visita primero todos los vecinos del nodo inicial, luego los vecinos de esos vecinos, y así sucesivamente. Es ideal para encontrar el camino más corto en grafos no ponderados (donde todas las aristas tienen el mismo peso).
Casos de uso típicos: distancia mínima en laberintos, número mínimo de pasos, componentes conectados, y verificar si un grafo es bipartito.
DFS — Búsqueda en Profundidad
DFS (Depth-First Search) explora tan lejos como sea posible por cada rama antes de retroceder. Se implementa con recursión (usando la pila de llamadas) o con una pila explícita. Es fundamental para detección de ciclos, ordenamiento topológico, componentes fuertemente conectados y la mayoría de los algoritmos de árboles.
📝 BFS vs DFS
BFS: distancia mínima, nivel por nivel. Usa más memoria (guarda todos los nodos del nivel actual).
DFS: exploración profunda, ciclos, topología. Usa menos memoria en grafos anchos pero puede apilar mucho en grafos profundos.
⚠ Advertencia
En DFS recursivo, si el grafo tiene miles de nodos encadenados (como una lista enlazada grande),
puedes agotar la pila de llamadas del sistema y causar un stack overflow. En ese caso,
implementa DFS iterativo con una pila explícita (std::stack).
Análisis de eficiencia
Complejidad Big-O: guía práctica
La notación Big-O describe el peor caso de crecimiento de un algoritmo. Al analizar código, busca
los bucles: un for simple sobre n elementos contribuye O(n). Dos for
anidados sobre los mismos n elementos dan O(n²). Una función recursiva que divide el problema a
la mitad en cada llamada suele ser O(log n) o O(n log n).
Las constantes se ignoran en Big-O: O(3n) = O(n). Los términos de menor orden también se eliminan: O(n² + n) = O(n²). Esto refleja que para entradas muy grandes, el término dominante determina el comportamiento.
Cómo calcular complejidad en la práctica
- Identifica el tamaño de la entrada: suele ser n, pero puede ser la longitud de una cadena, el número de vértices de un grafo, etc.
- Cuenta las operaciones dominantes: comparaciones, accesos a arreglo, llamadas a función.
- Si hay un
forde 1 a n que dentro llama asort, la complejidad total es O(n · n log n) = O(n² log n). - La recursión tiene un árbol de llamadas: el número de hojas y la profundidad determinan la complejidad.
Límites prácticos por tiempo de ejecución
| Complejidad | n máximo aprox. en 1 segundo | Contexto |
|---|---|---|
| O(1) — O(log n) | Cualquier n razonable | Búsqueda binaria, hash lookup |
| O(n) | ~10⁸ | Recorrido de arreglo, suma |
| O(n log n) | ~10⁷ | Ordenamiento, Merge Sort |
| O(n²) | ~10⁴ — 10⁵ | Dos bucles anidados |
| O(2ⁿ) | ~20 — 25 | Subconjuntos, fuerza bruta exponencial |
💡 Consejo final
Antes de optimizar prematuramente, comprueba que tu solución es correcta. Una solución O(n²) correcta es mejor que una O(n log n) con bugs. Optimiza solo cuando el análisis de complejidad indique que superarás el límite de tiempo.
Para ir más lejos
Fuentes y lecturas recomendadas
Las siguientes son fuentes de primera línea, ampliamente reconocidas en la comunidad académica y profesional. No inventamos ni fabricamos referencias.
-
Cormen, Leiserson, Rivest & Stein — Introduction to Algorithms (CLRS), 4ª ed.
El libro de referencia por excelencia. Cubre prácticamente todos los algoritmos clásicos con demostraciones formales y análisis de complejidad riguroso. -
Knuth — The Art of Computer Programming (Vols. 1–4A)
La obra más exhaustiva sobre el tema. Matemáticamente profunda. Recomendada para quienes buscan el fundamento teórico completo. -
Sedgewick & Wayne — Algorithms, 4ª ed.
Excelente equilibrio entre teoría y práctica. Incluye visualizaciones y está escrito de forma más accesible que CLRS. -
MIT OpenCourseWare — 6.006 Introduction to Algorithms y 6.046 Design and Analysis of Algorithms
Cursos completos, con notas, videos y tareas disponibles gratuitamente en ocw.mit.edu. -
Stanford University — CS161 (Algorithms) y materiales del Algorithms Specialization en Coursera
Tim Roughgarden ofrece explicaciones muy claras sobre divide y vencerás, grafos y programación dinámica. -
cp-algorithms.com
Referencia práctica orientada a programación competitiva. Cubre implementaciones detalladas de algoritmos avanzados con pseudocódigo y código C++.
📝 Cómo usar estas fuentes
No necesitas leer CLRS de principio a fin desde el primer día. Úsalo como diccionario: cuando encuentres un algoritmo nuevo, búscalo ahí para ver su demostración formal. Los cursos de MIT y Stanford son ideales para aprender en secuencia y ver los conceptos en movimiento.